ymdb-一个分布式键值存储系统
我的开源项目
ymdb 是我开源的一款简易的分布式键值存储系统,适用于分布式系统初学者练手或者应届生写上简历,这篇文章将对 ymdb 做一个全面的介绍(建议仅用作学习用途,应用于生产是危险的,因为 ymdb 尚不完善)。
ymdb 使用 Go 语言开发,从面试情况来看,面试官还是很喜欢问这个项目的,并且有几个面试官表示这样的项目比较抓眼球,因为它是一个偏底层的并且不是一个千篇一律(俗称“烂大街”)的项目,因此写在简历上不失为一个好的选择。
技术选型
要做一个分布式存储系统,需要考虑以下三个点:
- 存储
- 分区
- 复制
存储是设计一个存储系统必须要考虑的,而分区和复制则是设计一个分布式系统需要考虑的。
在存储部分,当前的键值存储有三种技术方案,一种是 RocksDB 采用的 LSMT(Log Structured Merge Tree) 方案;一种是 RoseDB 采用的 Bitcask 方案;一种是 Redis 的方案。考虑到我想做一个持久的键值存储系统,所以 Redis 这种基于内存的方式首先排除,Redis 的持久化仅用作备份以及主从复制,并不会从磁盘去拿数据。LSMT 实现起来较为复杂,且其虽然写效率很高,但读效率却较差,主要由于 LSMT 是在磁盘上的多层结构,可能要查好几层才能查到数据。因此,我最终选择 RoseDB 的方案来实现键值存储,即将所有的 key 存储在内存中,并将 key 对应的值在磁盘中的位置与 key 一同存放,而将 value 都存储在磁盘上,读取数据只需要一次磁盘IO,写入数据由于是追加写,可以利用到 page cache ,这样读写效率都很高。
在分区部分,我们要做的是对数据的分区,由于我们将所有的 key 都存放在内存中,所以内存的大小就是我们可以存储的数据量的瓶颈,所以我们需要进行数据分区,保证每个节点上只存储部分数据而不是全量数据,这样就使得存储系统中可以存储的数据总量不受单台计算机的内存和磁盘大小的约束。借鉴 Redis ,我采用一致性哈希来做数据分区,不过没有 Redis 那么复杂。
在容错部分,做为一个分布式的系统,必须具有容错的能力,现有的知名的分布式系统例如 hdfs 、gfs 以及 kafka 等都是通过将一份数据存储多份副本来保证可靠性的,ymdb 亦是如此,我设计一个分区内的多个节点存储当前分区数据的多个副本来提供容错性。我采用 Raft 算法来实现分区内节点间的分布式共识,首先 Raft 易于理解,其次 Raft 被许多知名开源软件广泛使用,例如 etcd 、tikv 、Consul 等。
整体架构
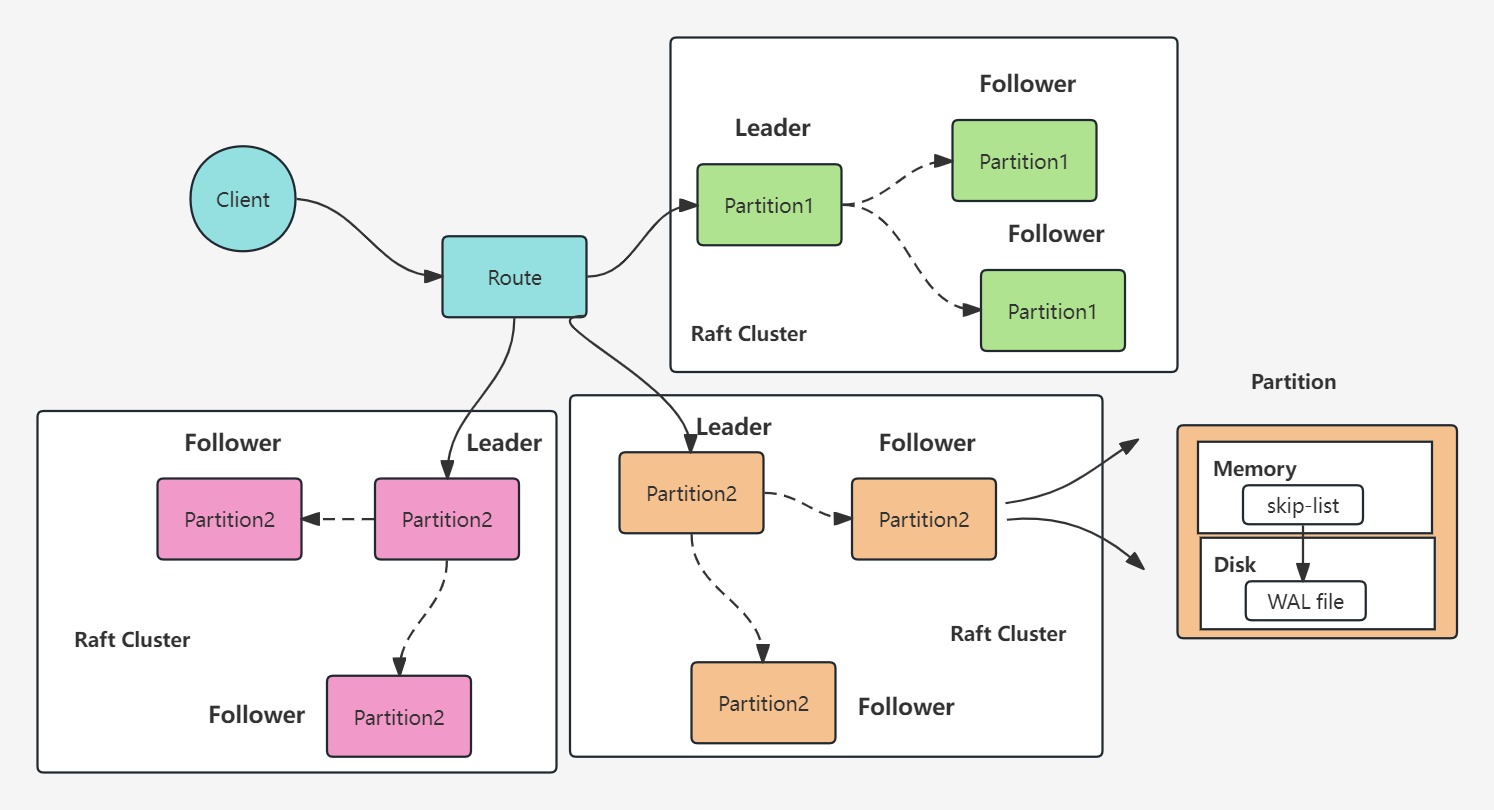
ymdb 的整体架构如图所示,客户端通过一致性哈希去确定数据所在的分区,每个分区内包含多个节点,存储本分区内数据的多个副本,在某一个具体的节点上,内存中存储所有的 key ,并使用跳表(skip-list)来作为 key 的索引结构以加快查找,value 以追加写的方式存储在磁盘上。
存储
内存
ymdb 在内存中存储所有的 key ,并采用跳表作为 key 的索引。选择跳表的原因在于其易于实现、维护成本低且范围查询友好,由于是内存索引,所以没有必要选择平衡树徒增维护成本。
相关代码位于项目的 index 包下,我这里直接采用了对第三方跳表实现的封装,put() 方法将 key 以及对应 value 所在的位置写入跳表;get()方法通过 key 获得其对应 value 在磁盘上的位置;delete()方法仅在跳表中删除指定 key 。
虽然我这里使用了第三方的跳表实现,但是跳表易于实现,也可以自己实现,我之前使用 C++ 实现过一版,具体思路在于使用 vector 作为跳表的节点,设置 vector 长度为跳表的高度,vector 的元素以下标顺序 0-i 分别存储该节点在跳表中的 0-i 层的信息,以随机的方式选择每个节点的高度。
磁盘
所有的 value 以追加写的方式存储在磁盘上的 WAL 文件中,这部分代码在项目的 db 包下,是 ymdb 存储引擎的实现,目前对数据的操作包含 put、get 以及 delete。
分区
采用一致性哈希来实现数据的分区,一致性哈希的基本原理可以看 一致性哈希算法,这里我也是采用了第三方实现,代码位于项目的 cluster-cli.go ,也就是说 ymdb 在客户端完成对于数据的定位,随后再向相应的分区发送数据的读写请求。
虽然我这里使用了第三方的一致性哈希实现,但是自己实现起来应该也较为简单,由于需要在哈希环上顺时针去寻找数据所在的分区,所以首先我们需要一个有序的数据结构,比如红黑树,首先对分区做哈希得到32位哈希值,存到红黑树中,之后对数据做哈希得到32位哈希值,在红黑树中搜索第一个比自己大的节点就是这个数据对应的分区。如果需要增加虚拟节点,只需要给真实分区加上一些信息,依旧做哈希得到哈希值,如果有数据映射到该分区,则可以进一步映射到真实的分区上。
复制
采用 Raft 算法来实现节点间的分布式共识,Raft 算法的基本原理可以看 Raft 共识算法总结。当客户端给一个分区发出写数据指令,该分区的 Leader 会来处理这个指令,Leader 负责将这条指令复制给其余的节点,其余的节点执行指令实现数据存储,并返回给 Leader ,当 Leader 收到集群中半数以上节点的响应时,就认为这条指令可以提交了,于是执行指令并给客户端返回。
ymdb 基于 Raft 算法,因此 ymdb 整体上是一个 CP 型的分布式系统,也就是说,保证强一致性并且具有分区容错性。
我采用了 HashiCorp 的 Raft 实现,代码位于项目的 raft 包下,application.go 下定义了自己的 FSM ,即有限状态机,主要是需要实现 Apply() 方法来定义日志应用的逻辑。由于我们客户端使用 grpc 来与 ymdb 集群做交互,所以还需要编写 proto 文件来定义 grpc 通信所需要的消息和服务,同时还需要在 application.go 中实现一个 rpc 服务端,实现 SendMsg() 方法处理 rpc 请求。另外,Raft 集群节点间的通信是第三方库实现好的,无需考虑。
通信
客户端采用 grpc 与多个 Raft 集群进行通信,客户端代码位于 cluster-cli.go 中,根据不同的指令和 key 向不同的数据分区发送不同的 rpc 请求,集群中任意一个节点收到 rpc 请求会把请求转发给 Leader 进行处理,Leader 处理消息的逻辑见 application.go 下的 rpcInterface 的 SendMsg() 方法,首先应用日志,之后从响应 channel 中取得结果;应用日志的具体逻辑在 dataTracker 的 Apply() 方法中,这里应用日志也就是交给存储引擎来执行数据读写命令,这里把消息放在了一个消息队列也就是 MsQueue 中,存储引擎会从中取命令然后执行,达到一个异步处理的效果。
崩溃恢复
为了实现崩溃一致性,节点应该具有崩溃恢复的能力,ymdb 在磁盘上额外存放了一个用于恢复的 WAL 文件,记录修改数据的指令,在每次执行修改类型的命令之前,首先将命令写入到日志中,类似于 MySQL 的 redo log ,这样即使节点崩溃。在节点恢复之后只需要执行日志中的指令即可恢复数据,实现崩溃一致性。
写入日志的代码位于项目的 route 包下,在 Handle() 方法中,根据消息类型执行不同的操作,只有 PUT 和 DELETE 操作才会去调用 writeWAL() 方法写入恢复日志。
崩溃恢复的代码位于项目的 db 包下的 Restore() 方法以及 NewDB() 方法,在创建 DB 对象时,如果发现指定目录下已经有日志文件,则置恢复状态位 isRestore 为真,执行恢复操作,否则创建新的日志文件。
优化
ymdb 目前尚有大量优化空间,我能想到的如下:
- 增加缓存系统。对于随机读取,无法利用到操作系统的 page cache ,导致每次查询稳定一次磁盘IO,是拖慢速度的,如果增加了缓存系统,便可以大大提升效率。然而引入缓存系统就必须要考虑其带来的数据不一致性,尚需要斟酌。
- 服务发现。目前系统中的节点数量和地址信息在数据库启动时就已经确定了,无法动态扩展,可以增加服务注册与发现机制来实现节点的动态增删,具体可以使用 zookeeper 来实现。
- 节点间数据迁移。由于使用了一致性哈希作为数据分区算法,增加和删除分区必然导致分区数据的变化,所以需要实现分区间数据的迁移,可以使用子进程来实现。
具体 ymdb 的使用可以参考 README.md 以及 示例。
面试
面试中对这个项目的考察多从以下几点进行提问:
- 为什么选择跳表作为内存索引,不选择别的
- 跳表的原理是什么,应该如何实现
- 为什么选择一致性哈希,还了解别的数据分区算法吗
- 一致性哈希知道怎么实现吗
- 一致性哈希存在哪些问题,如何解决
- 为什么选择 Raft 算法来做分布式共识,还了解别的分布式共识算法吗
- Raft 的领导选举介绍一下
- Raft 的 Leader 挂了会发生什么
- Raft 是强一致的吗,如何保证强一致的
- Raft 是如何解决脑裂问题的
- CAP 定理介绍一下
- ymdb 跟 Redis 集群有哪些不同之处
- 做过压测吗,性能如何
这就是我对 ymdb 的整体介绍,包括之后的优化思路以及面试常见问题,有任何问题可在评论区交流。
MIT6.824 的实验最终也会实现一个分布式的键值存储系统,然如果时间不充裕,听完 MIT 的全英课再自己实现 Raft 也需要较长时间,出于练手的考虑,直接采用第三方 Raft 快速构建一个分布式系统也是可以的,并且面试官很少会关注到 Raft 算法的具体实现。
版权声明: 如无特别声明,本文版权归 月梦の技术博客 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 ymdb-一个分布式键值存储系统 》
本文链接:https://ymiir.asia/%E5%BC%80%E6%BA%90/ymdb.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

熟悉Java、Go, 分布式系统以及大数据分析与处理

评论